What is a Reverse Proxy vs. Load Balancer? – NGINX
Reverse proxy servers and load balancers are components in a client-server computing architecture. Both act as intermediaries in the communication between the clients and servers, performing functions that improve efficiency. They can be implemented as dedicated, purpose-built devices, but increasingly in modern web architectures they are software applications that run on commodity hardware.
The basic definitions are simple:
A reverse proxy accepts a request from a client, forwards it to a server that can fulfill it, and returns the server’s response to the client.
A load balancer distributes incoming client requests among a group of servers, in each case returning the response from the selected server to the appropriate client.
But they sound pretty similar, right? Both types of application sit between clients and servers, accepting requests from the former and delivering responses from the latter. No wonder there’s confusion about what’s a reverse proxy vs. load balancer. To help tease them apart, let’s explore when and why they’re typically deployed at a website.
Load Balancing
Load balancers are most commonly deployed when a site needs multiple servers because the volume of requests is too much for a single server to handle efficiently. Deploying multiple servers also eliminates a single point of failure, making the website more reliable. Most commonly, the servers all host the same content, and the load balancer’s job is to distribute the workload in a way that makes the best use of each server’s capacity, prevents overload on any server, and results in the fastest possible response to the client.
A load balancer can also enhance the user experience by reducing the number of error responses the client sees. It does this by detecting when servers go down, and diverting requests away from them to the other servers in the group. In the simplest implementation, the load balancer detects server health by intercepting error responses to regular requests. Application health checks are a more flexible and sophisticated method in which the load balancer sends separate health-check requests and requires a specified type of response to consider the server healthy.
Another useful function provided by some load balancers is session persistence, which means sending all requests from a particular client to the same server. Even though HTTP is stateless in theory, many applications must store state information just to provide their core functionality – think of the shopping basket on an e-commerce site. Such applications underperform or can even fail in a load-balanced environment, if the load balancer distributes requests in a user session to different servers instead of directing them all to the server that responded to the initial request.
Reverse Proxy
Whereas deploying a load balancer makes sense only when you have multiple servers, it often makes sense to deploy a reverse proxy even with just one web server or application server. You can think of the reverse proxy as a website’s “public face. ” Its address is the one advertised for the website, and it sits at the edge of the site’s network to accept requests from web browsers and mobile apps for the content hosted at the website. The benefits are two-fold:
Increased security – No information about your backend servers is visible outside your internal network, so malicious clients cannot access them directly to exploit any vulnerabilities. Many reverse proxy servers include features that help protect backend servers from distributed denial-of-service (DDoS) attacks, for example by rejecting traffic from particular client IP addresses (blacklisting), or limiting the number of connections accepted from each client.
Increased scalability and flexibility – Because clients see only the reverse proxy’s IP address, you are free to change the configuration of your backend infrastructure. This is particularly useful In a load-balanced environment, where you can scale the number of servers up and down to match fluctuations in traffic volume.
Another reason to deploy a reverse proxy is for web acceleration – reducing the time it takes to generate a response and return it to the client. Techniques for web acceleration include the following:
Compression – Compressing server responses before returning them to the client (for instance, with gzip) reduces the amount of bandwidth they require, which speeds their transit over the network.
SSL termination – Encrypting the traffic between clients and servers protects it as it crosses a public network like the Internet. But decryption and encryption can be computationally expensive. By decrypting incoming requests and encrypting server responses, the reverse proxy frees up resources on backend servers which they can then devote to their main purpose, serving content.
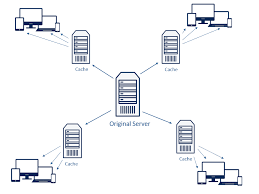
Caching – Before returning the backend server’s response to the client, the reverse proxy stores a copy of it locally. When the client (or any client) makes the same request, the reverse proxy can provide the response itself from the cache instead of forwarding the request to the backend server. This both decreases response time to the client and reduces the load on the backend server.
How Can NGINX Plus Help?
NGINX Plus and NGINX are the best-in-class reverse proxy and load balancing solutions used by high-traffic websites such as Dropbox, Netflix, and Zynga. More than 400 million websites worldwide rely on NGINX Plus and NGINX Open Source to deliver their content quickly, reliably, and securely.
NGINX Plus performs all the load-balancing and reverse proxy functions discussed above and more, improving website performance, reliability, security, and scale. As a software-based load balancer, NGINX Plus is much less expensive than hardware-based solutions with similar capabilities. The comprehensive load-balancing and reverse-proxy capabilities in NGINX Plus enable you to build a highly optimized application delivery network.
For details about how NGINX Plus implements the features described here, check out these resources:
Application Load Balancing with NGINX Plus
Application Health Checks with NGINX Plus
Session Persistence with NGINX Plus
Mitigating DDoS Attacks with NGINX and NGINX Plus
Compression and Decompression
SSL termination for HTTP and TCP
Content Caching in NGINX Plus

Why use a reverse proxy? – Loadbalancer.org
Simply because – it offers high availability, flexible security, great performance, and easy maintenance. For businesses struggling with web congestion due to heavy usage, using a reverse proxy is the right solution. Reverse proxies help to keep web traffic flowing – seamlessly. Along with improving server efficiency and ease of maintenance, they also provide an important layer of additional cybersecurity. Using a reverse proxy is also a great way for businesses to consolidate their internet presence. Read our blog to find out more about exactly what a reverse proxy is. How a reverse proxy works In a computer network, a reverse proxy server acts as a middleman – communicating with the users so the users never interact directly with the origin servers. Serving as a gateway, it sits in front of one or more web servers and forwards client (web browser) requests to those web servers. Web traffic must pass through it before they forward a request to a server to be fulfilled and then return the server’s response.
A reverse proxy is like a website’s ‘public face. ‘ Its address is the one advertised on the website. It sits at the edge of the site’s network to accept web browsers and mobile apps requests for the content hosted at the website. Reverse proxies make different servers and services appear as one single unit, allowing organizations to hide several different servers behind the same name – making it easier to remove services, upgrade them, add new ones, or roll them back. As a result, the site visitor only sees and not Reverse proxies help increase performance, reliability, and security. They provide load balancing for web applications and APIs. They can offload services from applications to improve performance through SSL acceleration, caching, and intelligent compression. By enforcing web application security, a reverse proxy also enables federated security services for multiple applications. To sum up, reverse proxy servers can:
Conceal the characteristics and existence of origin servers
Ease out takedowns and malware removals
Carry TLS acceleration hardware, letting them perform TLS encryption in place of secure websites
Spread the load from incoming requests to each of the servers that supports its own application area
Layer web servers with basic HTTP access authentication
Work as web acceleration servers that can cache both dynamic and static content, thus reducing the load on origin servers
Perform multivariate testing and A/B testing without inserting JavaScript into pages
Compress content to optimize it and speed up loading times
Serve clients with dynamically generated pages bit by bit even when they are produced at once, allowing the pages and the program that generates them to be closed, releasing server resources during the transfer time
Assess incoming requests via a single public IP address, delivering them to multiple web-servers within the local area network
What are the key benefits of using a reverse proxy? Security, load balancing, and ease of maintenance are the three most important benefits of using reverse proxy. Besides, they can also play a role in identity branding and proved online securityReverse proxies play a key role in building a zero trust architecture for organizations – that secures sensitive business data and systems. They only forward requests that your organization wants to serve. If you’re only serving web content, you can configure your reverse proxy to exclude all requests other than those for ports 80 and 443 – the default ports responsible for HTTP and HTTPS. This helps divert traffic based on type. Reverse proxies also make sure no information about your backend servers is visible outside your internal network, thus protecting them from being directly accessed by malicious clients to exploit any vulnerabilities. They safeguard your backend servers from distributed denial-of-service (DDoS) attacks – by rejecting or blacklisting traffic from particular client IP addresses, or limiting the number of connections accepted from each organizations looking at deploying proxy servers with extra teeth, reverse proxies can be easily upgraded to a creased scalability and flexibilityIncreased scalability and flexibility, is generally most useful in a load balanced environment where the number of servers can be scaled up and down depending on the fluctuations in traffic volume. Because clients see only the reverse proxy’s IP address, the configuration of your backend infrastructure can be changed freely. When excessive amounts of internet traffic slow down systems, the load balancing technique distributes traffic over one or multiple servers to improve the overall performance. It also ensures that applications no longer have a single point of failure. If and when one server goes down, its siblings can take over! Reverse proxies can use a technique called round-robin DNS to direct requests through a rotating list of internal servers. But if businesses have more demanding requirements, they can swap to a sophisticated setup that incorporates advanced load balancing accelerationReverse proxies can also help with ‘web acceleration’ – reducing the time taken to generate a response and return it to the entity brandingMost businesses host their website’s content management system or shopping cart apps with an external service outside their own network. Instead of letting site visitors know that you’re sending them to a different URL for payment, businesses can conceal that detail using a reverse proxy.
Caching commonly-requested dataBusinesses that serve a lot of static content like images and videos can set up a reverse proxy to cache some of that content. This kind of caching relieves pressure on the internal services, thus speeding up performance and improving user experience – especially for sites that feature dynamic is a reverse proxy different from a forward proxy? Simply because a forward proxy server sits in front of users, stopping origin servers from directly communicating with that user and a reverse proxy server sits in front of web servers, and intercepts requests. While a forward proxy acts for the client, guarding their privacy, a reverse proxy acts on behalf of the server. Forward proxies are used to capture traffic from managed endpoints; however, they don’t capture traffic from unmanaged endpoints like reverse proxies do. Forward proxies are used not for load balancing, but for passing requests to the internet from private networks through a firewall and can act as cache servers to reduce outward verse proxy and load balancers: what’s the correlation? A reverse proxy is a layer 7 load balancer (or, vice versa) that operates at the highest level applicable and provides for deeper context on the Application Layer protocols such as HTTP. By using additional application awareness, a reverse proxy or layer 7 load balancer has the ability to make more complex and informed load balancing decisions on the content of the message – whether it’s to optimise and change the content (HTTP header manipulation, compression and encryption) and/or monitor the health of applications to ensure reliability and availability. On the other hand, layer 4 load balancers are FAST routers rather than application (reverse) proxies where the client effectively talks directly (transparently) to the backend servers. All modern load balancers are capable of doing both – layer 4 as well as layer 7 load balancing, by acting either as reverse proxies (layer 7 load balancers) or routers (layer 4 load balancers). An initial tier of layer 4 load balancers can distribute the inbound traffic across a second tier of layer 7 (proxy-based) load balancers. Splitting up the traffic allows the computationally complex work of the proxy load balancers to be spread across multiple nodes. Thus, the two-tiered model serves far greater volumes of traffic than would otherwise be possible and therefore, is a great option for load balancing object storage systems – the demand for which has significantly exploded in the recent years. What are the common reverse proxy servers? Hardware load balancers, open-source reverse proxies, and reverse proxy software – offered by many vendors on the market. However, HAProxy, released in 2001 by Willy Tarreau, is the best reverse proxy out there – we highly recommend it because it’s fast and free. Over the years, HAProxy has evolved significantly to meet the changing needs of modern applications. Therefore, today, it’s being widely used by countless organizations around the world. HAProxy calls out reverse proxies as a critical element in achieving modern application delivery. By offering key capabilities like routing, security, observability, and more, reverse proxies form the bridge from inflexible traditional infrastructure to dynamic, distributed environments. Click around our blogs for more on HAProxy, transparent proxy, load balancing web proxies, and loads more.
Found in
Performance, High Availability

Using Load Balancers and Web Proxy Servers – Oracle Help Center
Deploying WebLogic Platform Applications
In a production environment, a load balancer or Web proxy server, as illustrated in the WebLogic Platform Domain Examples, is used to distribute client connection requests, provide load balancing and failover across the cluster, and provide security by concealing the local area network addresses from external users. A load balancer or Web proxy server allows all applications in the domain to be represented as a single address to external clients, and is required when using in-memory replication for client session information.
This section describes how to configure a hardware load balancer or Web proxy server.
Topics include:
Load Balancing with an External Hardware Load Balancer
Load Balancing with a Web Proxy Server
Considerations When Configuring Load Balancers and Web Proxy Servers
If you are using load balancing hardware, instead of a proxy, it must support a compatible passive or active cookie persistence mechanism, and SSL persistence, as described below:
Passive cookie persistence enables WebLogic Server to write a cookie containing session parameter information through the load balancer to the client. When using some hardware load balancers, you must configure the passive cookie persistence mechanism to avoid overwriting the WebLogic Server cookie that tracks primary and secondary servers used for in-memory replication. Specifically, you must set the following values:
String offset value to the Session ID value plus 1 byte for the delimiter character
String length to 10 bytes
Active cookie persistence is supported as long as the mechanism does not overwrite or modify the WebLogic HTTP session cookie. In this case, no additional configuration is required.
SSL persistence performs all encryption and decryption of data between clients and the cluster, and uses a plain text cookie on the client to maintain an association between the client and a server in the cluster.
For more information about active and passive cookie persistence and SSL persistence, see:
“Load Balancing HTTP Sessions with an External Load Balancer” in “Load Balancing for Servlets and JSPs” in Load Balancing in a Cluster in Using WebLogic Server Clusters.
“Configuring Load Balancers that Support Passive Cookie Persistence” in “Cluster Implementation Procedures” in Setting Up WebLogic Clusters in Using WebLogic Server Clusters.
For a description of connection and failover for HTTP session in a cluster with load balancing hardware, see “Accessing Clustered Servlets and JSPs with Load Balancing Hardware” in “Replication and Failover for Servlets and JSPs” in Failover and Replication in a Cluster in Using WebLogic Server Clusters.
If you are using an F5 BIG-IP hardware load balancer, see also Configuring BIG-IP Hardware with Clusters in Using WebLogic Server Clusters.
A Web proxy server maintains a list of WebLogic Server instances that host a clustered servlet or JSP, and forwards HTTP requests to those instances. Requests are forwarded on a round-robin basis, by default, as described in “Round Robin Load Balancing” in “Load Balancing for EJBs and RMI Objects” in Load Balancing a Cluster in Using WebLogic Server Clusters.
You can implement a Web proxy server using WebLogic Server with the HttpClusterServlet or by using one of the following Web servers and associated proxy plug-ins:
Netscape Enterprise Server with the Netscape (proxy) plug-in
Apache with the Apache Server (proxy) plug-in
Microsoft Internet Information Server with the Microsoft IIS (proxy) plug-in
Refer to the following table for information about configuring a Web proxy server to load balance servlets and JSPs.
The following lists considerations for configuring load balancers and Web proxy servers.
There may be circumstances in which you have to configure the WebLogic Workshop runtime to work with a Web server proxy. For more information, see “Proxy Server Setup” in Clustering Workshop Applications in the WebLogic Workshop Online Help.
To support automatic failover, WebLogic Server replicates the HTTP session state of clients that access clustered servlets and JSPs, and maintains them in memory, a file system, or a database. To utilize in-memory replication for HTTP session states, you must access the WebLogic Server cluster using either a collection of Web servers with identically configured WebLogic proxy servers or load balancing hardware.
The primary session state is stored on the server to which the client first connects. By default, WebLogic Server attempts to create session state replicas on a different machine than the one that hosts the primary session state. You can control where secondary states are placed using replication groups. A replication group is a preferred list of clustered servers to be used for storing session state replicas. For more information, see:
Enabling session replication in your applications, see Enabling Session Replication.
Defining replication groups, see Using Replication Groups in Using WebLogic Server Clusters.
HTTP session replication and how clustered servlets and JSP are accessed using load balancers, see “Replication and Failover for Servlets and JSPs” in Failover and Replication in a Cluster” in Using WebLogic Server Clusters.
When using T3 tunneling with a load balancer, you should set the load balancing algorithm to one of the server affinity algorithms to ensure that clients connect only through the tunneled connection. For more information, see “Round-Robin Affinity, Weight-Based Affinity, and Random Affinity” in “Load Balancing for Servlets and JSPs” in Load Balancing in a Cluster in Using WebLogic Server Clusters.
In addition to distributing HTTP traffic, external load balancers can distribute initial context requests that come from Java clients over T3 and the default channel. For a discussion of object-level load balancing, see “Load Balancing for EJBs and RMI Objects” in Load Balancing in a Cluster in Using WebLogic Server Clusters.
Frequently Asked Questions about load balancer and reverse proxy together
Can reverse proxy do load balancing?
Reverse proxies help increase performance, reliability, and security. They provide load balancing for web applications and APIs. They can offload services from applications to improve performance through SSL acceleration, caching, and intelligent compression.Jan 29, 2021
Is load balancer a proxy server?
A load balancer or Web proxy server allows all applications in the domain to be represented as a single address to external clients, and is required when using in-memory replication for client session information.
Is an ELB a reverse proxy?
As per my understanding we don’t use ELB as a reverse proxy. If you would like capture client’s IP address and using TCP listener then you would need to configure Proxy Protocol. However, if we are using HTTPS listener and want to know client’s IP then you would need to use X-Forwarded header.