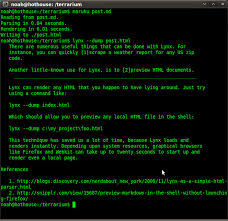
File Parsing and Data Analysis in Python Part I (Interactive …
Adnan Zaib Bhat
I am a mechanical engineer graduate interested in the digital world.
File Parsing and Data Analysis in Python Part I (Interactive Parsing and Data Visualisation)
LEAVE A COMMENT
Thanks for choosing to leave a comment. Please keep in mind that all comments are moderated according to our comment policy, and your email address will NOT be published. Let’s have a personal and meaningful conversation.
More projects by Adnan Zaib
Constrained Optimisation Using Lagrange Multipliers
Adnan Zaib
updated on Dec 23, 2018, 12:02am IST
Problem: Minimize: `5-(x-2)^2 -2(y-1)^2`; subject to the following constraint: `x + 4y = 3` 1) Lagrange Multipliers Lagrange multipliers technique is a fundamental technique to solve problems involving constrained problems. This method is utilised to find the local minima and maxima subjected to (at least one) equality… Read more
Schedule a counselling session

What is Parse? – Computer Hope
Updated: 12/29/2017 by
To parse data or information means to break it down into component parts so that its syntax can be analyzed, categorized, and understood.
If an error occurs while parsing information a parse error is generated. A parse error may happen for any of the following reasons.
Reasons why a parse error may happen
The file containing the data to be parsed does not exist.
The data to be parsed contains an error. If you downloaded the file causing the parse error, try downloading the file again or look for an updated version of the file. If possible, try downloading the file from a different site.
You may have insufficient permissions to access the file’s data.
The file’s data is not compatible with the version of your operating system or program.
Insufficient disk space. If a file is written to a drive (e. g., thumb drive or SD card) that doesn’t have enough space for the parsed results, an error is generated. Make sure the drive has enough space or move the file being parsed to your hard drive if it’s being run from removable media.
Parse error with Excel or another spreadsheet formula
A parse error can also be encountered with a spreadsheet formula if the formula is not formatted correctly. Formula parse errors may happen when extraneous special characters are included in the formula, such as an extra quote. In general, any syntax error in the formula causes a parse error.
Error, Programming terms, Strip

Parsing Process – an overview | ScienceDirect Topics
Software architectureXiaoyao Liang, in Ascend AI Processor Architecture and Programming, 2020ParsingDuring the parsing process, the Offline Model Generator supports the parsing of original network models in different frameworks, abstracts the network structure and weight parameters of the original model, and redefines the network structure by using the unified intermediate graph (IR Graph). The intermediate graph consists of a compute node and a data node. Compute node consists of TBE operators with different functions. The data node receives different tensor data and provides various input data for the entire network. This intermediate graph is composed of computing graphs and weights, covering all the original model information. The intermediate graph sets up a bridge between the deep learning framework and the Ascend AI software stack. In this way, the neural network model constructed by the external framework can be easily converted into the offline model supported by the Ascend AI full chapterURL: Parsing, Retrieval and Browsing: An Integrated and Content-Based SolutionH. J. Zhang,… H. Wu, in Readings in Multimedia Computing and Networking, 2002ABSTRACTThis paper presents an integrated solution for computer assisted video parsing and content-based video retrieval and browsing. The uniqueness and effectiveness of this solution lies in its use of video content information provided by a parsing process driven by visual feature analysis. More specifically, parsing will temporally segment and abstract a video source, based on low-level image analyses; then retrieval and browsing of video will be based on key-frames selected during abstraction and spatial-temporal variations of visual features, as well as some shot-level semantics derived from camera operation and motion analysis. These processes, as well as video retrieval and browsing tools, are presented in detail as functions of an integrated system. Also, experimental results on automatic key-frame detection are full chapterURL: An Integration Platform for Databanks and Analysis Tools in BioinformaticsThure Etzold,… Simon Beaulah, in Bioinformatics, 20035. 1. 1 The SRS Token ServerSRS has a unique approach for parsing data sources that has proved effective for supporting many hundreds of different formats. With traditional approaches, a parser would be written as a program. This program would then be run over the data source and would return with a structure, such as a parse tree that contains the data items to be extracted from the source. In the context of structured data retrieval, the problem with that approach is that depending on the task (e. g., indexing or displaying) different information must be extracted from the input stream. For instance, for data display, the entire description field must be extracted, but to index the description field needs to be broken up into separate words. A new approach was devised called token server. A token server can be associated with a single entity of the input stream, such as a databank entry, and it responds to requests for individual tokens. Each token type is associated with a name (e. g., description Line) that can be used within this request. The token server parses only upon request (lazy parsing), but it keeps all parsed tokens in a cache so repeated requests can be answered by a quick look-up into the cache. A token server must be fed with a list of syntactic and optionally semantic rules. The syntactic rules are organized in a hierarchic manner. For a given databank there is usually a rule to parse out the entire entry from the databank, rules to extract the data fields within that entry, and rules to process individual data fields. The parsed information can be extracted on each level as tokens (e. g., the entire entry, the data fields, and individual words within an individual data field). Semantic rules can transform the information in the flat file. For example, amino acid names in three-letter code can be translated to one-letter code or a particular deoxyribonucleic acid (DNA) mutation can be classified as a missense 5. 2 shows an example of how two different identifiers for protein mutations can be transformed into four different tokens using a combination of syntactic and semantic 5. 2. The SRS token server applied on mutation following example of Icarus code defines rules for the tokens AaChange, ProteinChangePos, and AaMutType for the first variation of the mutation key rules are specified in Icarus, the internal programming language of SRS. Icarus is in many respects similar to Perl [16]. It is interpreted and object-oriented with a rich set of functionality. Icarus extends Perl with its ability to define formal rule sets for parsing. Within SRS it is also used extensively to define and manipulate the SRS previous code example contains seven rule definitions. Each starts with a name, followed by a colon and then the actual rule, which is enclosed within ∼ characters. These rules are specified in a variant of the Extended Backus Naur Form (EBNF) [17] and contain symbols such as literals, regular expressions (delimited by / characters), and references to other rules. In addition they can have commands (delimited by { and}), which are applied either after the match of the entire rule (command at the beginning of the rule) or after matching a symbol (command directly after the symbol). In the example three different functions are called within commands. $In specifies the input tokens to which the rule can be applied. For example, AaChange specifies as input the token table Key, which is produced by the rule Key. $Out specifies that the rule will create a token table with the current rule. The command $Wrt writes a string into the token table opened by the current rule. For example, the $Wrt command following the reference to the In rule in the rule Key will write the line matched by In into the token table Key. Using commands $In and $Out, rules can be chained by feeding each other with the output token tables they produce. For example, rule AaChange processes the tokens in token table Key and provides the input for rule AaMutType. Lazy parsing means that only the rules necessary to produce a token table will be activated. To retrieve the Key tokens, the rules Key and Entry need to be processed. To obtain AaMutType, the rules AaMutType, AaChange, Key, and Entry are invoked. Production AaChange uses an associative list to convert three-letter amino acid codes to their one-letter equivalents. AaMutType is a semantic rule that uses standard mutation descriptions provided by AaChange to determine whether a mutation is a simple substitution or leads to termination of the translation frame by introducing a stop vantages of the token server approach are:♦It is easy to write a parser where the overall complexity can be divided into layers: entry, fields, and individual field contents. ♦The parser is very robust; a problem parsing a particular data field will not break the overall parsing process. ♦A rule set consists of simple rules that can be easily maintained. ♦Lazy parsing allows adding rules that will only be used in special circumstances or by only a few individuals. ♦Lazy parsing allows alternative ways of parsing to be specified (e. g., retrieval of author names as encoded in the databank or converted to a standard format). ♦The parser can perform reformatting tasks on the output (e. g., insertion of hypertext links) full chapterURL: Greenlaw, H. James Hoover, in Fundamentals of the Theory of Computation: Principles and Practice, 19987. 6 Parsing with Deterministic Pushdown AutomataIn practical parser construction, nondeterministic parsing is a problem, since the parser has to guess what production to apply. If the production eventually leads to failure, the parser has to backtrack to the guess and try the next production. This can result in much wasted problem lies in being unable to determine which production to apply at any particular point in the derivation. If there were only one possible choice, the parsing process would be deterministic and would not have the backtracking overhead. Of course, any reasonable grammar must have choices of productions to apply or the language would be uninteresting. So the trick is to design the grammar for the language so that, with a bit of look-ahead on the input stream, the parser can decide what production to ‘s look at Lexp and see how this process works. The idea is that the next symbol in the input stream should determine the production to be applied. This means that for a given nonterminal, the right-hand side of all but one production for that terminal must begin with a unique terminal symbol, and one can begin with a nonterminal. This way a unique production can be selected on the basis of the current input symbol. If the current symbol does not match any production, then the one that begins with a nonterminal is lying this idea we arrive at the following new grammar Gexp’ for Lexp:S→EE→(E)R|VRV→a|b|c|dR→+E|*E|AA→ΛWe leave the verification of the correctness of the grammar and the construction of the corresponding DPDA for Gexp’ as an full chapterURL: and StandardizationDavid Loshin, in The Practitioner’s Guide to Data Quality Improvement, 201115. 3 Tokens: Units of MeaningData values stored within data elements carry meaning in the context of the business process and the underlying data model. In addressing any of the error paradigms, the first step is identifying distinct meaningful concepts embedded in data values. When the conceptual and value domains associated with each data element are strictly controlled, the potential variability of the data values is likewise restricted. This concept is often manifested by imposing restrictions on the data producers. For example, a company’s web site may only allow a customer to select one of a list of valid values (such as “country” or “state”), and refuse to allow free-text typing. Another example is limiting the responses allowed within an interactive voice recognition inbound call system (“Press or say one for account balances”). However, at the same time, tight restrictions on data entry pose challenges to the people performing data entry, especially when one of those restrictions prevents a person from being able to complete a task. For example, if a data entry screen for new customer data requires that the user enter a “State” value from a drop-down list of the 50 U. S. states, the interface forces that user to enter incorrect data if the customer lives outside the United leads to two different conclusions – either the data entry process must be carefully reviewed to ensure that the application’s controls cover all of the potential cases, or (more likely) the controls will end up being loosened, allowing for more freedom, and consequently, more variance. And since data sets are often used for purposes for which they were not originally intended to be used, data values may sufficiently meet business needs in one context, but not meet the needs of any new contexts. In both of these cases, a combination of inspection and data cleansing techniques will institute some degree of control over the data acquisition process. 15. 3. 1 Mapping “Data” to “Information”In either of these situations, there is a challenge in mapping the actual values within data elements to their underlying meanings within each business context for which the data set is used. As value length increases, the constraints on structure diminish, with more information being crammed into the data element, and the precision with which one can define a conceptual/value domain are also diminished. And with the more complex data values, each “chunk” of data that is inserted into the data field may (or may not) carry information. The objective of the parsing and standardization process, then, is the data value and break out the individual information termine which chunks carry the arrange the identified chunks into a standard rmalize the chunks into an agreed-to format to reduce variability across the data set. 2 What Is a Token? What the first step, breaking out the information chunks, really means is that the parts of a data value that carry the meaning should be identified. Each of those pieces of information is called a token. A token is representative of all of the character strings used for a particular example, free-formed character strings that appear in a name data element actually may carry multiple pieces of information, such as “first name, ” “middle name, ” “title, ” “generational suffix, ” among others. Those tokens can be configured into one out of many recognizable patterns. If we are able to differentiate between the different token types – last names, first names, initials, punctuation, and so on – we can define different patterns for recognizing an individual’s name:•first_name first_name last_name (“Howard David Loshin”)•first_name initial last_name (“Howard D Loshin”)•initial first_name last_name (“H David Loshin”)•last_name, first_name (“Loshin, David”)•last_name, first_name first_name (“Loshin, Howard David”)•last_name, first_name initial (“Loshin, Howard D”)As is seen in these examples, individual characters, strings, and punctuation may be represented as tokens. And these are just a few of the hundreds, if not thousands of different patterns that can be configured based on a relatively small collection of token types. Although not all names will conform to these patterns, a large number types can be further refined based on the value domain. For example, if we can distinguish male first name tokens from female first name tokens, we can use the tokens to infer gender assignment. This distinction and recognition process starts by parsing the tokens and then rearranging the strings that mapped to those tokens through a process called full chapterURL: Analysis and Optimization TechniquesJames Bean, in SOA and Web Services Interface Design, 201019. 4. 2 Navigation and data graphsThe rationale for designing a uniform message structure is that most XML Parsers will navigate an XML message structure as top-down and left-to-right. All of the message elements of the message, including parent element complexTypes, are defined as “nodes” by the parser. Depending upon the type of XML parser, the structure of the document is exposed as the organized set of element nodes. The set of nodes can be exposed as in a memory model and roughly analogous to the natural tree root structure of the message (as with a DOM [Document Object Model] parser), or where individual nodes are events raised to the consuming application (as with a SAX [Simple API for XML] or StAX [Streaming API for XML] parser) as a series of of parser type can also impact performance. The DOM parser builds a tree model of the element nodes in memory. The building of the model can take considerable processing time and consume significant memory resources. However, the navigation after the model is created can often provide more capabilities to the consuming application. The SAX parser does not build an extensive in-memory model, and navigates the XML message in a serial manner. Each node is raised as an event to the processing application. The application can choose to consume the data and information for that node or to continue processing. A SAX parsing process is typically much more efficient than a DOM parsing process. However, the ability of the consuming application to navigate the XML message is more any of these parsers, the consuming application must in some manner navigate through the various nodes (or events), extract the data of interest, and continue processing. When there is a requirement for recursion, where a consuming application needs to revisit a previous message node or event, or where the message structure is largely irregular, navigation can become complex. The consuming application may be required to manage a set of pointers for already processed nodes. When the message structure is more uniform with fewer structural or element nesting irregularities, an XML parser and consuming application will perform better. A simple method for conceptualizing the uniformity of an XML message structure is to visualize it as a data graph. Unfortunately, there are currently no developer tools that provide this navigational data graph capability for XML messages and service interfaces. However, many XML editors such as XML Spy (Copyright 2003-2008 Altova GmbH, reprinted with permission of Altova) will apply a logical indent of nested elements and structures (see Figure 19. 3). An indented canonical message sample provides a reasonable visual representation, where the message designer can imagine walking through the hierarchy of the message as a consumer. Uniformity can be estimated by visualizing a vertical line drawn from top to bottom of the XML message. Data points can be imagined as the left angle bracket for each XML element open tag. The elements that would left-align to the imagined line are uniform. If the line were to move toward the right, other groups of nested elements would also 19. Visualization of a Navigational Data Graph(Copyright 2003-2008 Altova GmbH, reprinted with permission of Altova)However, significant degrees of variance in the depth of nesting between the various groups implies a nonuniform structure. A model where each group of indented elements (as data points) is assigned a value and incremented from “1 to n” defines the horizontal element spread. If each of the assigned values were used to compute a standard deviation or similar measure of delta, a higher number would imply a nonuniform structure (see Figure 19. 4) 19. Conceptualization of a Navigational Data Graph(Copyright 2003-2008 Altova GmbH, reprinted with permission of Altova)An optimal message structure for navigation and processing would have all of the elements left aligned to a vertical line running from the first indented child element under the root element of the message to the bottom of the message. However, this type of flat message structure is rarely the case. Most canonical message designs will naturally have varied examples of nested elements and structures and will have exploited the natural affinities and groupings of elements. The recommended optimization technique for a uniform message structure is to determine when there are a significant number of variations between nested elements and structures. The message structure can be reviewed, and where appropriate, elements can be full chapterURL: Reference GuideDavid Loshin, in Business Intelligence (Second Edition), 2013Data CleansingData cleansing is the process of finding errors in data and either automatically or manually correcting the errors. A large part of the cleansing process involves the identification and elimination of duplicate records; a large part of this process is easy, because exact duplicates are easy to find in a database using simple queries or in a flat file by sorting and streaming the data based on a specific key. The difficult part of duplicates elimination is finding those nonexact duplicates—for example, pairs of records where there are subtle differences in the matching key. Data cleansing, which we discuss in Chapter 12, employs a number of techniques, with some of the most prevalent being:▪Parsing, which is the process of identifying tokens within a data instance and looking for recognizable patterns. The parsing process segregates each word, attempts to determine the relationship between the word and previously defined token sets, and then forms patterns from sequences of tokens. When a pattern is matched, there is a predefined transformation applied to the original field value to extract its individual components, which are then reported to the driver applications. ▪Standardization, which transforms data into a standard form. Standardization, a prelude to the record consolidation process, is used to extract entity information (e. g., person, company, telephone number, location) and to assign some semantic value for subsequent manipulation. Standardization will incorporate information reduction transformations during a consolidation or summarization application. ▪Abbreviation expansion, which transforms abbreviations into their full form. There are different kinds of abbreviation. One type shortens each of a set of words to a smaller form, where the abbreviation consists of a prefix of the original data value. Examples include “INC” for incorporated and “CORP” for corporation. Another type shortens the word by eliminating vowels or by contracting the letters to phonetics, such as “INTL” or “INTRNTL” for international. A third form of abbreviation is the acronym, where the first characters of each of a set of words are composed into a string, such as “USA” for “United States of America. ”▪Correction, which attempts to correct those data values that are not recognized and to augment correctable records with the correction. Realize that the correction process can only be partially automated; many vendors may give the impression that their tools can completely correct invalid data, but there is no silver bullet. In general, the correction process is based on maintaining a set of incorrect values as well as their corrected forms. As an example, if the word International is frequently misspelled as “Intrnational, ” there would be a rule mapping the incorrect form to the correct form. Some tools may incorporate business knowledge accumulated over a long period of time, which accounts for large knowledge bases of rules incorporated into these products; unfortunately, this opens the door for loads of obscure rules that reflect many special full chapterURL: Medical Networks and MachinesSyed V. Ahamed, in Intelligent Networks, 20139. 5 Practical Use of MMsConsider the possible use of an MM in its role of assisting a medical worker, an inventor in medical sciences, or a medical-mathematician. Such an MM can uncover the noun objects and verb functions in the existing medical banks of similar subjects under the DDS (OCLC, 2003) or LoC classification by parsing the scientific papers, patents, books, etc. Note that the initial parsing is done for symbols and for operators. Both are standard procedures during the compilation of any higher-level language computer program (Aho et al., 2006). During the attribute parsing, it will generate the attributes list of each of the objects parsed. It can also analyze the relations between parsed medical objects, and primary, secondary relationships between objects and their attributes. The parsing process establishes a structure of prior knowledge of medicine in the Figure 9. 5, this systematic approach to medical processing is presented and in Figure 9. 6 as an exhaustive machine-aided-innovative design, processing methodology of an MM is depicted. The MM now serves as an intelligent medical research assistant to the medical 9. 5. Parsing and analyzing the medical knowledge centric objects (MKCOs) in the existing KBs to generate synthesized MKCO that are optimized to suit the current socioeconomic settings. MNO, medical noun object; MPF, medical verb function; R, relationships between MNOs, MPFs, and MNOs and MPFs; Attr, attributes of MNOs and adjectives of 9. 6. A computational framework for processing knowledge with KPUs that reconstitute objects, their functions, relationships to suit the solution to social and human problems. EO, embedded noun object; MPF, verb function; R, relationships between MNOs, MPFs, and MNOs and MPFs; Attr, attributes of MNOs and adjectives of machine compiles, analyzes, and optimizes the synthesized knowledge as it is derived from the existing knowledge from the local and Internet KBs (Ahamed, 2007). The syntactic rules for the deduction of the new noun objects, verb functions, and relationships are based on scientific evidence, logical deduction, and mathematical reasoning. The semantic rules for establishing the relations between MNOs, MPFs, and between MNOs and MPFs are substantiated from the local and global the four compilation procedures (parsing, lexical, syntactic, and semantic analysis; Aho et al., 2006) that have been well established in the complier theory of traditional computers are performed by the medical compiler software (SW) for the MM. The conventional compiler design concepts and their corresponding procedures become applicable in the compilation of medical principle, the medical knowledge machine will execute medical programs as efficiently as a computer would execute any higher-level language programs in any computer system. It is our contention that well-constructed HW and medical-ware (MW) will perform the medical functions as efficiently as numeric, logic, AI, and object-oriented function as existing computer systems. In addition, the MM has the semihuman capacity to invent medical processes, objects, their attributes, etc., as it processes medical knowledge and innate ability to invent and innovate is built in MMs since it constantly checks the optimality of every noun object (MNO) and verb function (MPF) that it accesses and executes. The convolution between the two is examined thoroughly because of the network access to the Web this section, we present a computational platform for executing medical programs by deploying suitably designed MPUs and a series of medical compiler software modules. It is capable of generating new medical science–oriented knowledge from existing MPFs and MNOs. There is a possibility that these medical research assistants can invent based of WWW medical knowledge of current literature. The functioning of the MM can be made generic like the PCs that handle a large number of common programs for a large community of users or specific to specialized users in any discipline such as medicine, cardiovascular systems, cancer, radiation therapy, and so on. All the tools and techniques embedded in AI are transplanted in the science of medicine or any branch of medicine. The medical KBs are tailored accordingly to conform to the subject or owledge processing is based on object processing, and objects constitute the nodal points in the structure of knowledge. The links and relationships between the nodes offer different types of architectures that can be tailored to meet the user needs. Verb functions that operate on the nodes can transform existing inventions and literature into customized signatures for the next generation of computer full chapterURL: Schema BasicsJames Bean, in SOA and Web Services Interface Design, 201010. 6 NamespacesA namespace can be a difficult and somewhat ambiguous concept to comprehend. In the case of XML Schemas and a corresponding XML message, an XML namespace serves to uniquely identify declarations. 5 That is, an XML declaration such as an element can be declared to participate in a namespace and therefore inherits the namespace as part of its identification and potentially as part of its exposed tag name. The named declarations of an XML message or of an XML Schema are identified by tag names (see Figure 10. 20). However, elements with tags such as “< ItemID/ > ” and “< Color/ > ” might be defined to multiple XML Schemas that are all assembled as part of the service interface. Unfortunately, like named elements and similar declarations can “collide. ” XML Schema declarations and XML encoded content can be associated with and participate in different namespaces, which helps to avoid 10. 20. Example Namespace Prefixed XML Message ElementsThe targetNamespace is also the overall namespace of the schema, and it can be used as a named reference for the schema and its content. Parser validation of an XML message requires that the XML message refers to one or more XML Schemas. Further, the element tags of the XML message must map by name and position to the intended structure of the referenced XML Schemas. To check that the message is in compliance, a syntactical reference from the XML message to the XML Schema is required. This reference to the XML Schemas can be declared within the XML message itself as either a “noNamespaceSchemaLocation” or a “schemaLocation” value, or for some parsers, it can be declared externally as a parameter and used during the parsing process. Both types of schema location attributes refer to an XML value of a “noNamespaceSchemaLocation” attribute declaration is used to reference an XML schema that does not have a targetNamespace. Alternatively, the value of a “schemaLocation” attribute references an XML Schema that includes a targetNamespace. Namespaces were previously described in Chapter 7, “The Service Interface—Contract. ” The difference between a schema with a target namespace and one without a namespace might seem trivial. However, there are important capabilities of both. Reference of the namespace qualified XML Schema from an XML message or instance requires the schemaLocation attribute, with a value pair. The value pair will include the schema name (and possibly a path name) as well as the value of the XML Schema targetNamespace attribute. Alternatively, reference of the unqualified XML Schema (without a targetNamespace) from an XML message or instance requires the noNamespaceSchemaLocation attribute, with a value representing the schema name and an optional directory schema location reference of the XML message also includes a file name or namespace reference and can be declared without a location or directory path (sometimes referred to as a “relative” location) or with a specified path (sometimes referred to as an “absolute” location). Resolving the location and acquiring a copy of the referenced XML Schema is left to the parser (see Figure 10. 21). The file name and location information are known as “parser hints” and are not strictly required by the specification. However, and from experience, a directory path to a named XML Schema file and a namespace are almost always sufficient for the validating parser to find and access the referenced 10. 21. Schema References from an XML Message InstanceWhen the XML Schema has a declared targetNamespace, that namespace name and assigned prefix can also be used to identify specific elements of the XML message that map to and participate in that namespace. As another form of namespace qualification, other more specific namespaces can also be defined to the XML Schema that override the targetNamespace and are applied to qualifying declarations. While namespace participation helps to avoid named object collisions, it also uniquely identifies each namespace-qualified declaration. When the XML Schema does not have a targetName-space, its declarations are said to participate in no same notion of a namespace can be exploited for reuse. An XML Schema that has a set of element declarations, such as a postal address structure, can then be referenced and reused by other XML full chapterURL: Constructs of a Knowledge MachineSyed V. Ahamed, in Next Generation Knowledge Machines, 20149. 4 Practical Use of KMsConsider the possible use of a KM in its role of assisting a knowledge worker, an inventor in a scientific domain, or a mathematician. Such a KM can uncover the noun objects and verb function in the existing knowledge banks of similar subjects under the DDS (OCLC, 2003) or LoC classification by parsing the scientific papers, patents, books, etc. Note that the initial parsing is done for symbols and operators are standard procedures during the compilation of any higher level language computer program (Aho et al., 2007). During the attribute parsing it will generate the attribute list of each of the objects parsed. It can also analyze the relations between parsed objects, and primary, secondary relationships between objects and their attributes. The parsing process establishes a structure of prior knowledge in the Figure 9. 5, a systematic approach to knowledge processing is presented and in Figure 9. 6, an exhaustive design processing methodology of a KM is depicted. This figure is divided in two sections (Figure 9. 6a and b) with a program controlled bus switch in the 9. Parsing and analyzing the knowledge centric objects (KCOs) in the existing knowledge bases to generate synthesized KCOs that are optimized to suit the current socioeconomic settings. NO, noun object; VF, verb function, R, relationships between NOs, VFs, and NOs and VFs; Atr., attributes of NOs and also adverbs of 9. (A and B) Architectural configuration of processing knowledge system with multiple KPUs that reconstitute embedded noun objects, their functions, relationships to suit the application and machine compiles, analyzes, and optimizes the sy
Frequently Asked Questions about what is file parsing
What is meant by parsing a file?
To parse data or information means to break it down into component parts so that its syntax can be analyzed, categorized, and understood.Dec 29, 2017
What is the parsing process?
Parsing, which is the process of identifying tokens within a data instance and looking for recognizable patterns. The parsing process segregates each word, attempts to determine the relationship between the word and previously defined token sets, and then forms patterns from sequences of tokens.
What is parse example?
Parse is defined as to break something down into its parts, particularly for study of the individual parts. An example of to parse is to break down a sentence to explain each element to someone. … Parsing breaks down words into functional units that can be converted into machine language.